Il metodo k-Nearest Classificazione
Classificare un valore target basandosi sui suoi vicini più vicini.
Algoritmo K-Nearest
L'algoritmo k-Nearest Neighbors (KNN) è un algoritmo di apprendimento supervisionato utilizzato per problemi di classificazione e regressione.L'obiettivo principale di KNN è classificare un'istanza di dati o prevedere il suo valore di output basandosi sui valori delle istanze di dati vicine nel set di addestramento.
Il metodo K-Nearest Neighbors (KNN) è un algoritmo supervisionato che classifica un punto basandosi sulle classi dei suoi k vicini più prossimi nel dataset di training, determinati utilizzando una metrica di distanza (es. Euclidea).
I passi dell'algoritmo sono:
1.Calcolo delle distanze: Misura la distanza tra il punto da predire e tutti i punti del dataset di training.
2.Selezione dei vicini: Identifica i k punti più vicini.
3.Determinazione della classe: La classe del punto da predire è quella più frequente tra i vicini (maggioranza).
KNN è generalmente utilizzato quando si dispone di un set di dati relativamente piccolo e non lineare e non si conosce la distribuzione dei dati.
Tuttavia, può essere computazionalmente costoso per set di dati di grandi dimensioni poiché richiede il calcolo delle distanze tra tutti i punti di dati nel set di addestramento.
Gli obiettivi principali di KNN sono:
- Classificazione: assegnare una classe a un'istanza di dati in base alle classi delle istanze di dati vicine.
- Regressione: prevedere il valore numerico di output di un'istanza di dati in base ai valori delle istanze di dati vicine.
Ecco un esempio di codice Python che implementa KNN utilizzando il set di dati Iris e verifica l'accuratezza del modello:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Carica il set di dati Iris
iris = load_iris()
X = iris.data
y = iris.target
# Dividi il set di dati in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Crea il classificatore KNN
knn = KNeighborsClassifier(n_neighbors=3)
# Addestra il classificatore sul set di addestramento
knn.fit(X_train, y_train)
# Esegui la previsione sul set di test
y_pred = knn.predict(X_test)
# Calcola l'accuratezza del modello
accuracy = accuracy_score(y_test, y_pred)
print("Accuratezza del modello KNN:", accuracy)
# Visualizza i risultati utilizzando matplotlib
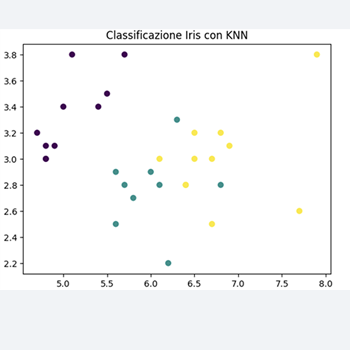
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap='viridis')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Classificazione Iris con KNN')
plt.show()
Questo codice carica il set di dati Iris, lo divide in set di addestramento e di test, addestra un classificatore KNN sul set di addestramento e valuta l'accuratezza del modello.
Infine, visualizza i risultati della classificazione utilizzando Matplotlib.