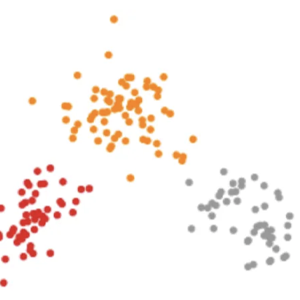
Linear Discriminant Analysis
La Linear Discriminant Analysis (LDA), una tecnica di machine learning utilizzata principalmente per problemi di classificazione e riduzione della dimensionalità.
Linear Discriminant Analysis (LDA)
La Linear Discriminant Analysis (LDA) è una tecnica di machine learning utilizzata principalmente per problemi di classificazione e riduzione della dimensionalità.L'obiettivo principale dell'LDA è trovare una combinazione lineare di caratteristiche che separa al meglio due o più classi. In pratica, l'LDA cerca di massimizzare la separazione tra le classi minimizzando al contempo la varianza all'interno di ciascuna classe.
Quando si usa la LDA
La LDA è particolarmente utile quando si ha un problema di classificazione con più classi e si desidera ridurre il numero di variabili di input per migliorare le prestazioni del modello o per visualizzare i dati in due o tre dimensioni.È spesso utilizzata nei seguenti casi:
- Classificazione: Per assegnare nuovi esempi a una delle classi predefinite.
- Riduzione della dimensionalità: Per ridurre il numero di variabili mantenendo la maggior parte dell'informazione discriminante.
Correlazione con il Teorema di Bayes
LDA assume che le variabili predittive siano normalmente distribuite e che ogni classe abbia la stessa matrice di covarianza.Sotto queste assunzioni, LDA può essere vista come una variante del Classificatore Bayesiano, in cui si stima la probabilità di appartenenza di un esempio a una classe specifica.
Esempio con il dataset Iris
L'esempio seguente mostra come utilizzare la LDA con il dataset Iris, dividere il dataset in set di addestramento e test, eseguire una previsione sui dati di test e valutare le prestazioni del modello utilizzando una matrice di confusione e un classification report.
# Importiamo le librerie necessarie
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.datasets import load_iris
# Carichiamo il dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Dividiamo il dataset in set di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Inizializziamo il modello LDA
lda = LinearDiscriminantAnalysis()
# Addestriamo il modello sui dati di training
lda.fit(X_train, y_train)
# Effettuiamo previsioni sui dati di test
y_pred = lda.predict(X_test)
# Importiamo la matrice di confusione e il classification report
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# Stampiamo i risultati
print("Matrice di Confusione:")
print(conf_matrix)
print("\nClassification Report:")
print(class_report)
Spiegazione dei Risultati
- Matrice di Confusione: Mostra il numero di previsioni corrette e incorrette divise per classe.
- Classification Report: Include metriche come precision, recall, f1-score per ciascuna classe, fornendo una visione dettagliata delle prestazioni del modello.
Questo esempio illustra come la LDA può essere utilizzata per classificare correttamente le diverse specie di fiori nel dataset Iris e valutare l'efficacia del modello tramite metriche standard.