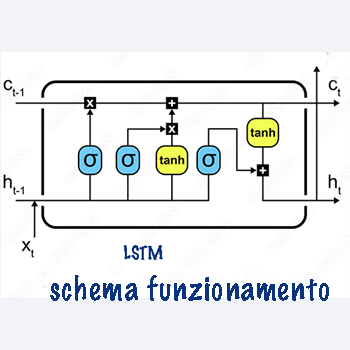
Addestramento LSTM
Addestrare una rete ricorrente (RNN) con Keras. Codice Python
Codice e Addestramento LSTM
I passi- Importiamo le librerie
- Creaiamo un vocabolario
- Prepariamo i dati con il processo di token e padding
- Addestraimo la rete
- Verifichiamo se abbiamo overfitting
per maggiori dettagli sul significato del codiceclicca qui
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import LSTM, Dense, Embedding
# Generazione casuale di parole inglesi e traduzioni italiane
english_words = ['hello', 'world', 'cat', 'dog', 'house', 'car', 'tree', 'sun', 'moon', 'book']
italian_words = ['ciao', 'mondo', 'gatto', 'cane', 'casa', 'macchina', 'albero', 'sole', 'luna', 'libro']
# Creazione del DataFrame
vocabolario = pd.DataFrame({'Inglese': english_words, 'Italiano': italian_words})
# Tokenizzazione delle parole
tokenizer_eng = Tokenizer()
tokenizer_ita = Tokenizer()
tokenizer_eng.fit_on_texts(vocabolario['Inglese'])
tokenizer_ita.fit_on_texts(vocabolario['Italiano'])
vocab_size_eng = len(tokenizer_eng.word_index) + 1
vocab_size_ita = len(tokenizer_ita.word_index) + 1
# Sequenze di input e output
X = tokenizer_eng.texts_to_sequences(vocabolario['Inglese'])
y = tokenizer_ita.texts_to_sequences(vocabolario['Italiano'])
# Padding delle sequenze
maxlen = max(len(seq) for seq in X) # Lunghezza massima delle sequenze
X = pad_sequences(X, maxlen=maxlen, padding='post')
y = pad_sequences(y, maxlen=maxlen, padding='post')
# Codifica one-hot per l'output
y = np.eye(vocab_size_ita)[y]
# Dividi il dataset in training e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Definizione del modello LSTM
embedding_dim = 50
model = Sequential()
model.add(Embedding(vocab_size_eng, embedding_dim, input_length=maxlen))
model.add(LSTM(128, return_sequences=True))
model.add(Dense(vocab_size_ita, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Addestramento del modello
history = model.fit(X_train, y_train, epochs=50, validation_data=(X_test, y_test), verbose=2)
# Valutazione del modello
train_loss, train_acc = model.evaluate(X_train, y_train, verbose=0)
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print(f'Accuracy del training set: {train_acc}')
print(f'Accuracy del test set: {test_acc}')
# Verifica dell'overfitting
if train_loss < test_loss:
print("Non c'è overfitting.")
else:
print("C'è overfitting.")