Alberi Decisionali e Matrice Confusionale
La matrice di confusione mostra il confronto tra le classi effettive e quelle predette dal modello.
Alberi e Matrice Confusionale
In questo articolo definiamo la Matrice Confusionale
La matrice di confusione è uno strumento utilizzato per valutare le prestazioni di un modello di classificazione.
Essa mostra il confronto tra le classi effettive e quelle predette dal modello.
Le righe rappresentano le classi effettive, mentre le colonne rappresentano le classi predette.
Ogni cella indica il numero di occorrenze per ciascuna combinazione di classe effettiva e predetta.
Questo aiuta a identificare errori specifici nelle predizioni del modello.
Creaiamo un data set
vani piano zona prezzo y
0 3 1 1 180000 1
1 6 2 2 120000 2
2 1 3 7 30000 0
3 4 4 6 100000 1
4 7 0 8 25000 0
5 2 5 5 75000 1
6 5 2 4 90000 2
7 3 3 3 110000 1
Questo Data Set considera nelle features le caratteristiche di un appartamento
La variabile target y
- Non Interessante=0
- Da Discutere=1
- Interessante=2
Usiamo questo Data Set per prevedere se una offerta può essere interessante
Verrà usata la funzione DecisionTreeClassifier()
Creazione del Dataset
data = {
'vani': [3, 6, 1, 4, 7, 2, 5, 3],
'piano': [1, 2, 3, 4, 0, 5, 2, 3],
'zona': [1, 2, 7, 6, 8, 5, 4, 3],
'prezzo': [180000, 120000, 30000, 100000, 25000, 75000, 90000, 110000],
'y': [1, 2, 0, 1, 0, 1, 2, 1]
}
df = pd.DataFrame(data)
print("Dataset:")
print(df)
Definiamo i dati come un dizionario Python, dove le chiavi rappresentano i nomi delle colonne e i valori sono liste di dati. Convertiamo poi questo dizionario in un DataFrame Pandas, che è una struttura dati tabellare molto usata per l'analisi dei dati.
Infine, stampiamo il DataFrame.
Suddivisione del Dataset in Training e Test Set
X = df[['vani', 'piano', 'zona', 'prezzo']]
y = df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
Separiamo le caratteristiche (`vani`, `piano`, `zona`, `prezzo`) dalla variabile target (`y`). Utilizziamo `train_test_split` della libreria sklearn per dividere i dati in un training set (75% dei dati) e un test set (25% dei dati).
La variabile `random_state` garantisce che la suddivisione sia riproducibile.
Addestramento del Modello
clf = DecisionTreeClassifier(criterion='gini', max_depth=15, random_state=42)
clf.fit(X_train, y_train)
Creiamo un classificatore ad albero decisionale (`DecisionTreeClassifier`) utilizzando il criterio di impurità Gini e impostando una profondità massima di 15. Addestriamo il modello utilizzando il training set (`X_train` e `y_train`).
Validazione del Modello
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
Utilizziamo il modello addestrato per fare previsioni sul test set (`X_test`). Calcoliamo l'accuratezza del modello confrontando le previsioni (`y_pred`) con i valori effettivi (`y_test`) usando `accuracy_score`.
Calcoliamo anche la matrice di confusione (`confusion_matrix`) per una valutazione dettagliata delle prestazioni del modello.
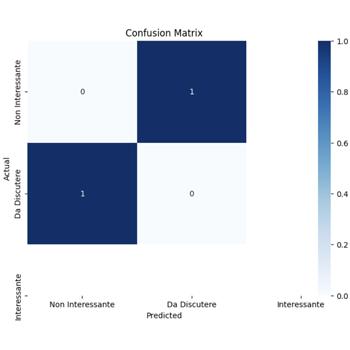
Visualizzazione della Matrice di Confusione
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Non Interessante', 'Da Discutere', 'Interessante'], yticklabels=['Non Interessante', 'Da Discutere', 'Interessante'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
Creiamo una figura e visualizziamo la matrice di confusione utilizzando `seaborn` (`sns.heatmap`). Le etichette sugli assi rappresentano le classi predette e reali. La matrice di confusione aiuta a identificare specifici errori di classificazione.
Predizione di un Nuovo Punto Dati
new_data = {'vani': [4], 'piano': [2], 'zona': [5], 'prezzo': [85000]}
new_df = pd.DataFrame(new_data)
new_pred = clf.predict(new_df)
new_df['y'] = new_pred
Creiamo un nuovo punto dati con caratteristiche specifiche (`vani`, `piano`, `zona`, `prezzo`). Convertiamo i dati in un DataFrame Pandas e utilizziamo il modello per fare una previsione sulla classe di interesse (`y`). Aggiungiamo questa previsione al DataFrame `new_df`.
Stampa dei Risultati
print(df)
print(f"Accuracy: {accuracy}")
print(new_df)
Stampiamo il dataset iniziale, l'accuratezza del modello e le previsioni per il nuovo punto dati per visualizzare tutti i risultati del processo.
Codice Completo
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Creazione del dataset
data = {
'vani': [3, 6, 1, 4, 7, 2, 5, 3],
'piano': [1, 2, 3, 4, 0, 5, 2, 3],
'zona': [1, 2, 7, 6, 8, 5, 4, 3],
'prezzo': [180000, 120000, 30000, 100000, 25000, 75000, 90000, 110000],
'y': [1, 2, 0, 1, 0, 1, 2, 1]
}
df = pd.DataFrame(data)
# Stampa del dataset
print("Dataset:")
print(df)
# Suddivisione del dataset in training e test set
X = df[['vani', 'piano', 'zona', 'prezzo']]
y = df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# Addestramento del DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion='gini', max_depth=15, random_state=42)
clf.fit(X_train, y_train)
# Predizione sul test set
y_pred = clf.predict(X_test)
# Calcolo dell'accuratezza
accuracy = accuracy_score(y_test, y_pred)
# Calcolo della matrice di confusione
conf_matrix = confusion_matrix(y_test, y_pred)
# Creazione di un nuovo punto dati
new_data = {'vani': [4], 'piano': [2], 'zona': [5], 'prezzo': [85000]}
new_df = pd.DataFrame(new_data)
new_pred = clf.predict(new_df)
# Aggiunta della nuova previsione al dataframe
new_df['y'] = new_pred
# Visualizzazione della matrice di confusione
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Non Interessante', 'Da Discutere', 'Interessante'], yticklabels=['Non Interessante', 'Da Discutere', 'Interessante'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
# Mostra tutti gli output
print(df)
print(f"Accuracy: {accuracy}")
print(new_df)