DB Scan
Identificare cluster di forma arbitraria e gestire il rumore nei dati.
Cos'è il DBSCAN?
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) è un algoritmo di clustering basato sulla densità che è particolarmente utile per identificare cluster di forma arbitraria e per gestire il rumore nei dati. A differenza di algoritmi come K-means, DBSCAN non richiede che venga specificato il numero di cluster a priori.
Invece, utilizza due parametri principali:
1. Epsilon (ε): La distanza massima tra due punti affinché uno possa essere considerato come parte del cluster dell'altro.
2. **MinPts**: Il numero minimo di punti necessari per formare un cluster.
Come funziona il DBSCAN
1.Punti Core: Un punto è un punto core se ha almeno `MinPts` punti nel raggio ε.2. Punti di Bordo: Un punto è un punto di bordo se si trova entro la distanza ε di un punto core, ma non ha abbastanza punti per essere esso stesso un punto core.
3. Punti di Rumore: Un punto che non è né un punto core né un punto di bordo.
DBSCAN inizia con un punto non visitato, lo considera un punto core se ci sono abbastanza punti nel suo intorno ε, e itera espandendo i cluster a partire dai punti core.
Esempio di Utilizzo del DBSCAN
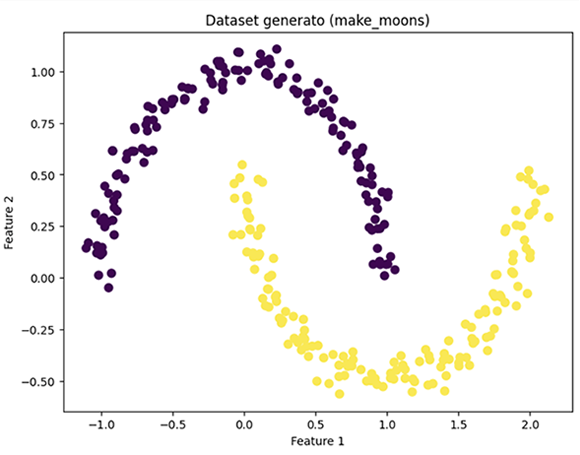
Utilizzeremo il dataset generato con `make_moons`, che crea un dataset di due mezze lune, un classico esempio di dati non linearmente separabili.Generazione del Dataset e Visualizzazione
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
# Generazione del dataset
X, y = make_moons(n_samples=300, noise=0.05, random_state=42)
# Visualizzazione del dataset
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='viridis')
plt.title('Dataset generato (make_moons)')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
Applicazione del DBSCAN
from sklearn.cluster import DBSCAN
# Applicazione del clustering DBSCAN
dbscan = DBSCAN(eps=0.2, min_samples=5)
clusters = dbscan.fit_predict(X)
Visualizzazione dei Cluster
# Visualizzazione dei cluster
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=clusters, s=50, cmap='viridis')
plt.title('Clustering DBSCAN')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
Spiegazione del Codice
1.Generazione del Dataset: Utilizziamo `make_moons` per generare un dataset sintetico con 300 campioni e rumore aggiunto per simulare dati non linearmente separabili.2. Visualizzazione del Dataset: Visualizziamo il dataset generato con un grafico a dispersione, colorando i punti in base alla loro etichetta.
3. Applicazione del DBSCAN: Utilizziamo `DBSCAN` da `sklearn.cluster` per applicare il clustering basato sulla densità al dataset. Impostiamo ε a 0.2 e `min_samples` a 5.
4. Visualizzazione dei Cluster: Visualizziamo i cluster risultanti con un grafico a dispersione, utilizzando colori diversi per rappresentare i diversi cluster identificati da DBSCAN.