Codice per Gated Recurrent Units GRU
Codice ottenuto con chatGPT
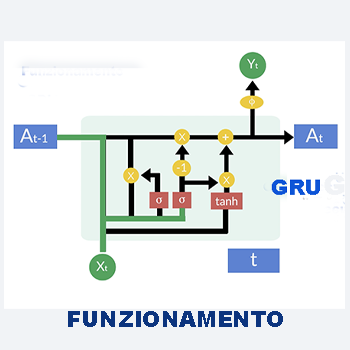
GRU, Gated Recurrent Units, una RNN con meno parametri delle LSTM. Si addestra più velocemente.
Codice per una rete Gated Recurrent Units GRU
Il codice che segue utilizza una rete GRU al posto della LSTM.Le GRU, o Gated Recurrent Units, sono un tipo di rete neurale ricorrente che ha meno parametri rispetto alle LSTM e quindi potrebbe addestrarsi più velocemente.
Tuttavia, le LSTM sono generalmente più potenti e possono gestire meglio le lunghe dipendenze temporali. La scelta tra GRU e LSTM dipende dalle esigenze specifiche del problema e dalle risorse computazionali disponibili.
Codice completo per addestrae una rete GRU
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import GRU, Dense, Embedding
# Generazione casuale di parole inglesi e traduzioni italiane
english_words = ['hello', 'world', 'cat', 'dog', 'house', 'car', 'tree', 'sun', 'moon', 'book']
italian_words = ['ciao', 'mondo', 'gatto', 'cane', 'casa', 'macchina', 'albero', 'sole', 'luna', 'libro']
# Creazione del DataFrame
vocabolario = pd.DataFrame({'Inglese': english_words, 'Italiano': italian_words})
# Tokenizzazione delle parole
tokenizer_eng = Tokenizer()
tokenizer_ita = Tokenizer()
tokenizer_eng.fit_on_texts(vocabolario['Inglese'])
tokenizer_ita.fit_on_texts(vocabolario['Italiano'])
vocab_size_eng = len(tokenizer_eng.word_index) + 1
vocab_size_ita = len(tokenizer_ita.word_index) + 1
# Sequenze di input e output
X = tokenizer_eng.texts_to_sequences(vocabolario['Inglese'])
y = tokenizer_ita.texts_to_sequences(vocabolario['Italiano'])
# Padding delle sequenze
maxlen = max(len(seq) for seq in X) # Lunghezza massima delle sequenze
X = pad_sequences(X, maxlen=maxlen, padding='post')
y = pad_sequences(y, maxlen=maxlen, padding='post')
# Codifica one-hot per l'output
y = np.eye(vocab_size_ita)[y]
# Dividi il dataset in training e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Definizione del modello GRU
embedding_dim = 50
model = Sequential()
model.add(Embedding(vocab_size_eng, embedding_dim, input_length=maxlen))
model.add(GRU(128, return_sequences=True))
model.add(Dense(vocab_size_ita, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Addestramento del modello
history = model.fit(X_train, y_train, epochs=50, validation_data=(X_test, y_test), verbose=2)
# Valutazione del modello
train_loss, train_acc = model.evaluate(X_train, y_train, verbose=0)
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print(f'Accuracy del training set: {train_acc}')
print(f'Accuracy del test set: {test_acc}')
# Verifica dell'overfitting
if train_loss < test_loss:
print("Non c'è overfitting.")
else:
print("C'è overfitting.")
Dettaglio del Codice
Analizziamo nel dettaglio il codice:
1. `embedding_dim = 50`: Questa istruzione imposta la dimensione dell'embedding, che è la dimensione dello spazio vettoriale in cui le parole verranno rappresentate. Ad esempio, se `embedding_dim` è impostato su 50, ogni parola nel vocabolario verrà rappresentata da un vettore di 50 dimensioni.
2. `model = Sequential()`: Qui si crea un modello sequenziale. Un modello sequenziale è una sequenza lineare di strati neurali, dove ciascuno strato ha esattamente un tensore di input e uno di output. Questo è uno dei modelli più comuni in Keras per definire reti neurali feedforward.
3. `model.add(Embedding(vocab_size_eng, embedding_dim, input_length=maxlen))`: Aggiunge uno strato di embedding al modello. Lo strato di embedding mappa le parole nel vocabolario in vettori densi di dimensione `embedding_dim`. `vocab_size_eng` è la dimensione del vocabolario inglese, `embedding_dim` è la dimensione dello spazio vettoriale di embedding e `input_length` è la lunghezza massima delle sequenze di input.
4. `model.add(GRU(128, return_sequences=True))`: Aggiunge uno strato GRU al modello. Una GRU è un tipo di rete neurale ricorrente che utilizza un meccanismo di gating per gestire il flusso di informazioni attraverso la rete nel tempo. `128` è il numero di unità GRU nel layer, e `return_sequences=True` indica che il layer deve restituire le sequenze complete anziché solo l'ultimo output.
5. `model.add(Dense(vocab_size_ita, activation='softmax'))`: Aggiunge uno strato denso con attivazione softmax. Questo strato produce l'output finale del modello, che è una distribuzione di probabilità su tutto il vocabolario italiano. `vocab_size_ita` è la dimensione del vocabolario italiano e `softmax` viene utilizzato come funzione di attivazione per produrre le probabilità.
In sintesi, questo codice definisce un modello sequenziale che utilizza uno strato di embedding per rappresentare le parole, seguito da uno strato GRU per catturare le dipendenze temporali nei dati di input e infine uno strato denso con attivazione softmax per produrre le previsioni finali.