Learning Rate Adattivo
Una tecnica per regolare automaticamente il tasso di apprendimento.
Adaptive Moment Estimation: Adam
learning rate adattivo
Il learning rate, o tasso di apprendimento, indica quanto i pesi della rete neurale vengono aggiornati durante l'ottimizzazione dei parametri del modello.Un learning rate troppo alto può portare a oscillazioni e instabilità durante l'addestramento, mentre un learning rate troppo basso può causare un addestramento lento o la convergenza a minimi locali.
Con il learning rate adattivo, il tasso di apprendimento non è fisso ma varia durante l'addestramento in base alle caratteristiche dei dati e alla loro evoluzione nel tempo.
Ciò consente di adattare dinamicamente il tasso di apprendimento per ottenere una convergenza più rapida e una maggiore stabilità durante l'addestramento.
Questo approccio mira a migliorare l'efficienza dell'ottimizzazione riducendo il rischio di convergere in minimi locali o di oscillare intorno al minimo globale.
Un esempio di algoritmo di ottimizzazione con learning rate adattivo è l'Adaptive Moment Estimation= Adam, che si adatta automaticamente il learning rate per ogni parametro della rete in base al gradiente storico.
Questo permette di assegnare tassi di apprendimento più elevati ai parametri con gradiente più scarsi e viceversa.
Di seguito è riportato un esempio di utilizzo di Adam come ottimizzatore in Keras per addestrare un modello di rete neurale sul dataset Fashion MNIST:
import numpy as np
from keras.datasets import fashion_mnist
from keras.models import Sequential
from keras.layers import Flatten, Dense
from keras.optimizers import Adam
import matplotlib.pyplot as plt
# Caricamento del dataset
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# Normalizzazione dei valori dei pixel
X_train = X_train / 255.0
X_test = X_test / 255.0
# Creazione del modello
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# Compilazione del modello con Adam come ottimizzatore
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Addestramento del modello
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
# Stampa della loss e dell'accuratezza
print("Valore della funzione di costo (loss)")
print(history.history.keys())
# Plot della loss e dell'accuratezza
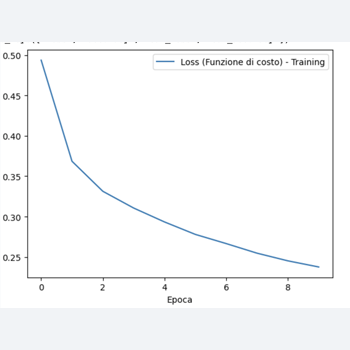
plt.plot(history.history['loss'], label='Loss (Funzione di costo) - Training')
plt.xlabel('Epoca')
plt.ylabel('Valore')
plt.legend()
plt.show()
Nell'esempio precedente, l'ottimizzatore Adam è utilizzato per addestrare il modello di rete neurale.
Adam, acronimo di Adaptive Moment Estimation, è un algoritmo di ottimizzazione che combina concetti presi da due altri algoritmi: Adagrad e RMSprop.
Questo metodo adattivo calcola il tasso di apprendimento per ogni parametro, fornendo una maggiore precisione e una convergenza più rapida rispetto ad altri ottimizzatori.
Ecco come è utilizzato :
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
In questa riga di codice:
- `optimizer='adam'` specifica che stiamo utilizzando l'ottimizzatore Adam per addestrare il modello. Questo significa che durante l'addestramento, Adam si occuperà di aggiornare i pesi della rete neurale in modo da minimizzare la funzione di perdita.
- `loss='categorical_crossentropy'` specifica la funzione di costo che il modello cercherà di minimizzare durante l'addestramento. Nel caso di un problema di classificazione multiclasse come quello del dataset Fashion MNIST, la perdita categorica di entropia incrociata è comunemente utilizzata.
- `metrics=['accuracy']` specifica le metriche da valutare durante l'addestramento del modello. In questo caso, stiamo monitorando l'accuratezza del modello durante l'addestramento.
Quindi, questo codice configura il modello per essere addestrato utilizzando l'ottimizzatore Adam, minimizzando la perdita categorica di entropia incrociata e monitorando l'accuratezza durante l'addestramento.