regressione Logistica
Per prevedere l'appartenenza a una classe
regressione logistica
E' un modello di classificazione utilizzato per assegnare correttamente le osservazioni a diverse classi.È particolarmente adatto per problemi di classificazione binaria o multiclasse.
Funzionamento della regressione logistica
- Input: Prendiamo n esempi, dal nostro insieme di addestramento, ciascuno composto da m attributi.
- Pesi: Calcoliamo una distribuzione di pesi W che ci permetta di classificare correttamente gli esempi tra le varie classi.
-
Combinazione lineare: Per ogni campione, calcoliamo la combinazione lineare z delle caratteristiche X degli esempi e dei relativi pesi W:
\[ z = x_0 \cdot w_0 + \ldots + x_m \cdot w_m \] -
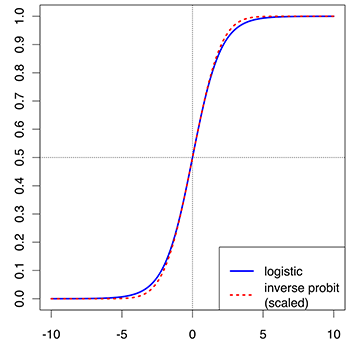
Funzione logistica (sigmoid): Passiamo la combinazione lineare z attraverso la funzione logistica (sigmoid) per ottenere la probabilità di appartenenza del campione alle classi:
\[ \phi(z) = \frac{1}{1 + e^{-z}} \]
La funzione sigmoid produce una curva a forma di S che rappresenta la distribuzione delle probabilità.
Esempio in Python
Supponiamo di voler classificare i fiori del dataset Iris in base a due attributi:larghezza del petalo e lunghezza del petalo.
Ecco come addestrare un modello di regressione logistica utilizzando Scikit-Learn:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Carica il dataset Iris
iris = datasets.load_iris()
X = iris.data[:, [2, 3]] # Prendiamo solo due attributi
y = iris.target
# Suddividi il dataset in training e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Standardizza le variabili
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
# Addestra il modello di regressione logistica
lr = LogisticRegression(C=1000.0, random_state=0)
lr.fit(X_train_std, y_train)
# Valuta l'accuratezza del modello
y_pred = lr.predict(X_test_std)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuratezza del modello: {accuracy:.2f}")