Normalizzazione & Standardizzazione
Due tecniche utilizzate per rendere più uniforme la distribuzione dei valori delle variabili
La normalizzazione e la standardizzazione sono due tecniche comuni utilizzate nel pre-processing dei dati per rendere più uniforme la distribuzione dei valori delle variabili.
Normalizzazione
- Significato La normalizzazione scala i valori delle variabili in modo che si trovino entro un intervallo specifico, di solito tra 0 e 1.
- Uso È utile quando i dati hanno una distribuzione non uniforme e si desidera che tutte le variabili abbiano la stessa scala.
- Vantaggi Può aiutare ad evitare problemi derivanti da unità di misura diverse e a migliorare la convergenza degli algoritmi di machine learning.
- Svantaggi Può non gestire bene gli outlier se l'intervallo dei dati è ampio.
Standardizzazione
- Significato La standardizzazione trasforma i valori delle variabili in modo che abbiano una media zero e una deviazione standard unitaria.
- Uso È utile quando le variabili hanno scale diverse e si desidera che abbiano la stessa media e deviazione standard.
- Vantaggi Aiuta ad evitare problemi derivanti da unità di misura diverse, migliora la convergenza degli algoritmi e può migliorare l'interpretazione dei coefficienti nei modelli lineari.
- Svantaggi Può amplificare l'impatto degli outlier se presenti.
Quando usarle
Ecco quando è consigliabile utilizzare la standardizzazione, la normalizzazione o entrambe.
Standardizzazione
-
Quando usarla
La standardizzazione è particolarmente utile quando le variabili hanno scale diverse e si desidera che abbiano la stessa media e deviazione standard.
È comunemente utilizzata in algoritmi che dipendono dalla distanza tra le osservazioni, come il K-Nearest Neighbors (KNN) e il Support Vector Machine (SVM). -
Esempi
Quando si utilizzano algoritmi basati sulla distanza, come il KNN.
Quando si utilizzano algoritmi lineari, come la regressione logistica o le Support Vector Machine (SVM).
Normalizzazione
-
Quando usarla
La normalizzazione è utile quando si desidera scalare i valori delle variabili in un intervallo specifico, di solito tra 0 e 1.
È utile in algoritmi che richiedono che i valori si trovino entro un intervallo specifico, come le reti neurali. - Esempi Quando si utilizzano algoritmi di apprendimento automatico che richiedono valori compresi tra 0 e 1, come alcune reti neurali.
Entrambe
-
Quando usarle
In alcuni casi, può essere vantaggioso applicare sia la standardizzazione che la normalizzazione.
Ad esempio, in algoritmi sensibili alla scala e alla distribuzione dei dati, come le reti neurali, potrebbe essere utile normalizzare i dati prima di applicare la standardizzazione per garantire che i dati siano nella gamma desiderata e che abbiano una distribuzione simile. - Esempi Quando si utilizzano reti neurali: prima di applicare la standardizzazione, normalizzare i dati per assicurarsi che si trovino nell'intervallo desiderato e poi applicare la standardizzazione per garantire una distribuzione simile dei dati.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.datasets import load_iris
# Carica il dataset Iris
iris = load_iris()
data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# Normalizzazione
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
normalized_data = pd.DataFrame(data=normalized_data, columns=data.columns)
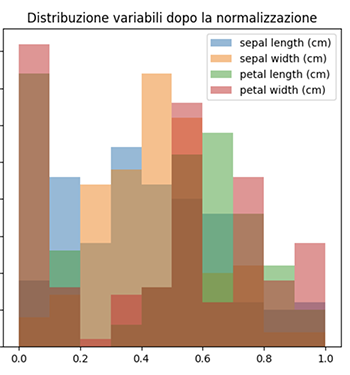
# Visualizza il grafico delle variabili normalizzate
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
for column in normalized_data.columns:
plt.hist(normalized_data[column], alpha=0.5, label=column)
plt.title('Distribuzione variabili dopo la normalizzazione')
plt.legend()
# Standardizzazione
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)
standardized_data = pd.DataFrame(data=standardized_data, columns=data.columns)
# Visualizza il grafico delle variabili standardizzate
plt.subplot(1, 2, 2)
for column in standardized_data.columns:
plt.hist(standardized_data[column], alpha=0.5, label=column)
plt.title('Distribuzione variabili dopo la standardizzazione')
plt.legend()
plt.tight_layout()
plt.show()
In questo esempio, normalizziamo e standardizziamo il dataset Iris e mostriamo i grafici delle distribuzioni delle variabili prima e dopo l'applicazione di ciascuna tecnica.