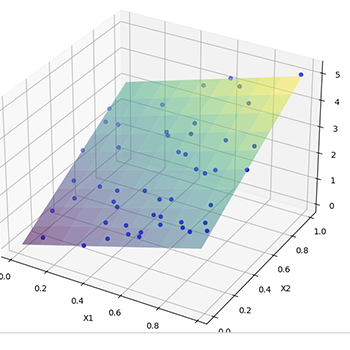
Regressione piu' variabili
Data set con piu' variabili, definire una correlazione, regressione a più variabili
Carico database e decido le colonne
In questo primo step, abbiamo individuato un Db dal sitokaagle Relativo al costo delle case a Milano
Usato l'istruzione corr() e creato una heatmap per verificare le realazioni tra colonne
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Leggi il database dal file CSV
file_path = "percorso/casemi.csv"
df = pd.read_csv(file_path)
# Mostra le prime 5 righe del database
print("Prime 5 righe del database:")
print(df.head())
# Calcola la correlazione tra le variabili
correlation = df.corr()
# Crea una heatmap per visualizzare la correlazione
plt.figure(figsize=(10, 8))
sns.heatmap(correlation, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Heatmap della correlazione tra variabili')
plt.show()
Scelta delle colonne
In base allo step precendente utilizzato le colonneprice, m2, year_of_build, elevator, renewable_energy_performance_index_KWh/m2, floor_level
Le righe con valori numerici sono state eliminate
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# Percorso del file CSV
file_path = "/Applications/MAMP/htdocs/livio.bollini/SingoloArticolo-html/int-artificiale/algoritmi/casemi.csv"
# Seleziona le colonne da utilizzare
selected_columns = ['price', 'm2', 'year_of_build', 'elevator', 'renewable_energy_performance_index_KWh/m2', 'floor_level']
# Leggi il database dal file CSV
df = pd.read_csv(file_path, usecols=selected_columns)
# Sostituisci i valori non numerici con NaN
df = df.apply(pd.to_numeric, errors='coerce')
# Rimuovi le righe con valori NaN
df = df.dropna()
# Visualizza il nome delle colonne
print("Nomi delle colonne:")
print(df.columns)
# Dividi il dataset in training e test (80% training, 20% test)
X = df.drop(columns=['price']) # Variabili indipendenti
y = df['price'] # Variabile dipendente (target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Applica la regressione lineare multipla
model = LinearRegression()
model.fit(X_train, y_train)
# Fai previsioni sul set di test
y_pred = model.predict(X_test)
# Calcola il coefficiente di determinazione (R² score)
r2 = r2_score(y_test, y_pred)
print("R² score:", r2)
R² score: 0.39195898625496994