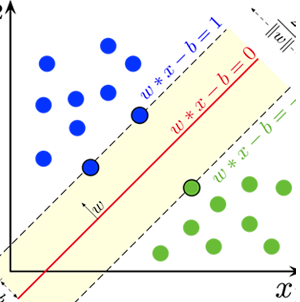
Support Vector Machine classificazione
Nei problemi di classificazione, SVM per trovare un iperpiano che separi le classi nel modo più netto possibile.
Support Vector Machine nei problemi di classificazione
La Support Vector Machine (SVM) è un potente algoritmo di apprendimento supervisionato utilizzato per la classificazione e la regressione.Nei problemi di classificazione, l'obiettivo della SVM è trovare un iperpiano che separi le classi nel modo più netto possibile.
Questo iperpiano è determinato massimizzando il margine tra i punti di dati di entrambe le classi più vicini all'iperpiano, noti come vettori di supporto.
Quando si usa la SVM
La SVM è utile quando:-Si ha un dataset con molte caratteristiche e si desidera trovare una frontiera di decisione chiara tra le classi.
-Si ha un dataset di piccole o medie dimensioni.
-Si richiede una classificazione robusta anche in presenza di dati rumorosi o outliers.
-Si vogliono evitare problemi di overfitting grazie all'uso di tecniche di regolarizzazione integrate.
Differenza tra LinearSVC e Kernel SVC
LinearSVC Utilizza un kernel lineare ed è adatto quando i dati sono linearmente separabili o quasi linearmente separabili.
È più efficiente in termini di calcolo per dataset con molte caratteristiche.
Kernel SVC Utilizza kernel non lineari come RBF, polinomiale, ecc., per gestire dati non linearmente separabili. Questa versione è più flessibile ma anche più costosa computazionalmente.
Esempio con LinearSVC
Caricamento del Dataset e Definizione delle Features e del Target
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from mlxtend.plotting import plot_decision_regions
# Caricamento del dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
columns = ["Variance", "Skewness", "Curtosis", "Entropy", "Class"]
data = pd.read_csv(url, header=None, names=columns)
# Definizione delle features e della target
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# Divisione del dataset in training e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Modello LinearSVC
# Modello LinearSVC
linear_svc = LinearSVC(random_state=42)
linear_svc.fit(X_train, y_train)
y_pred_linear = linear_svc.predict(X_test)
# Matrice di confusione e report di classificazione per LinearSVC
print("LinearSVC Confusion Matrix:")
print(confusion_matrix(y_test, y_pred_linear))
print("\nLinearSVC Classification Report:")
print(classification_report(y_test, y_pred_linear))
# Visualizzazione del confine decisionale (usando solo le prime due features per semplicità)
plt.figure(figsize=(7, 6))
plot_decision_regions(X_train[:, :2], y_train, clf=linear_svc, legend=2)
plt.title("LinearSVC Decision Boundary")
plt.show()
Esempio con Kernel SVC
Il caricamento del dataset e la definizione delle features e del target rimangono gli stessi dell'esempio precedente.Modello Kernel SVC
from sklearn.svm import SVC
# Modello Kernel SVC
kernel_svc = SVC(kernel='rbf', random_state=42)
kernel_svc.fit(X_train, y_train)
y_pred_kernel = kernel_svc.predict(X_test)
# Matrice di confusione e report di classificazione per Kernel SVC
print("Kernel SVC Confusion Matrix:")
print(confusion_matrix(y_test, y_pred_kernel))
print("\nKernel SVC Classification Report:")
print(classification_report(y_test, y_pred_kernel))
# Visualizzazione del confine decisionale (usando solo le prime due features per semplicità)
plt.figure(figsize=(7, 6))
plot_decision_regions(X_train[:, :2], y_train, clf=kernel_svc, legend=2)
plt.title("Kernel SVC Decision Boundary")
plt.show()